Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
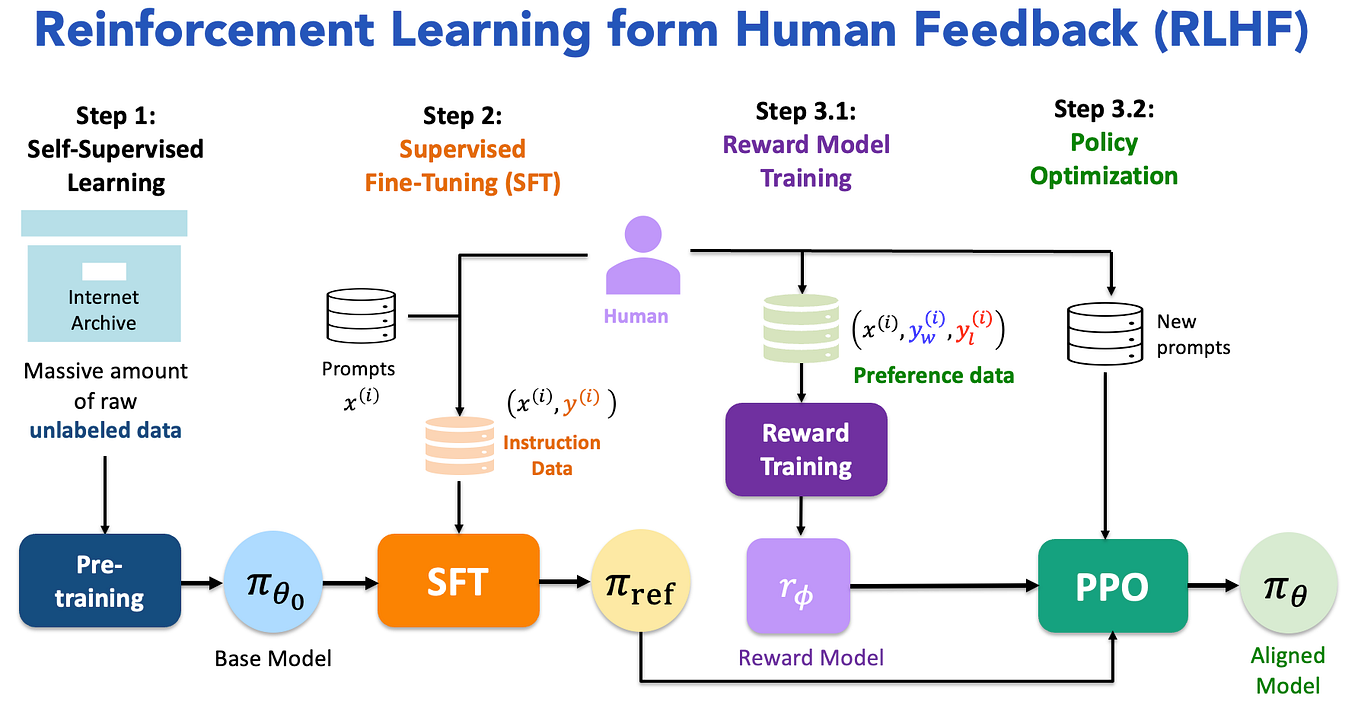
Dissecting Batching Effects in GPT Inference
GPT Inference - a Hugging Face Space by prerana1205
Tutorial: Running inference with OpenAI's GPT OSS 20B using W&B ...
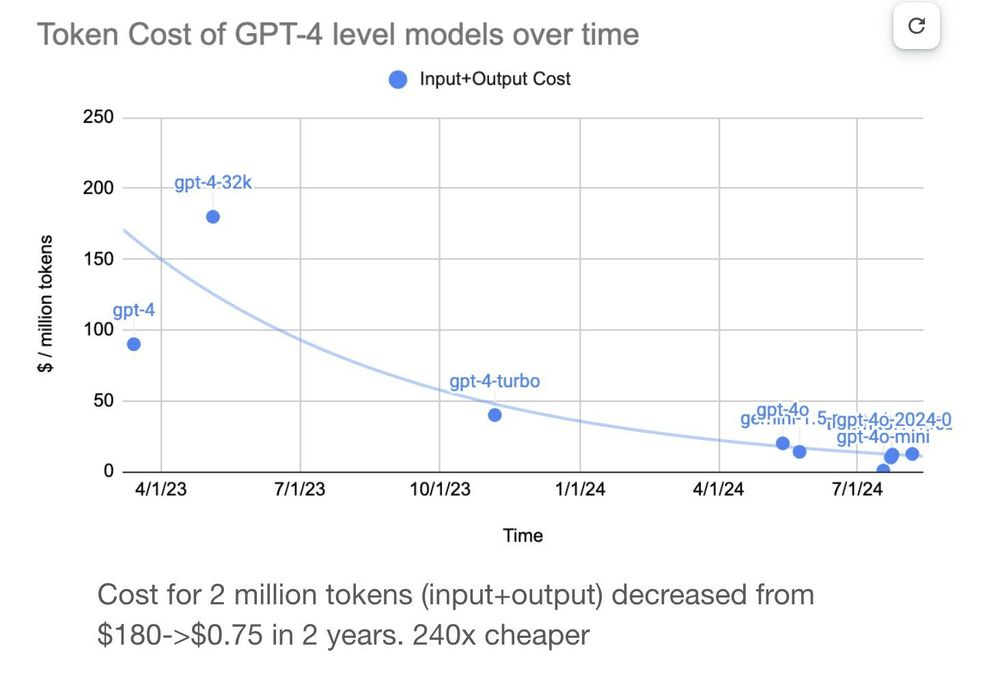
GPT - OSS: Inference Cost Drops 75% Suddenly, Achieves 4 - fold ...
Inference On Nano GPT | PDF
Optimizing GPT Inference with Multi-threading | Course Hero
Figure 1 from SIGMA: Secure GPT Inference with Function Secret Sharing ...
PoPETs Proceedings — SIGMA: Secure GPT Inference with Function Secret ...
[BugFix] GPT inference error when pipeline_para_size > 1 and int8_mode ...
GPT SoVits Inference - a Hugging Face Space by Yunshansongbai
d2s3-2 Sigma: Secure GPT Inference with Function Secret Sharing - Neha ...
SIGMA: Secure GPT Inference with Function Secret Sharing (RWC 2024 ...
Private Enterprise GPT on Any Cloud with Inference APIs - Autoize
Free Video: GPT OSS Release - Inference and Fine-Tuning from Trelis ...
question about SIGMA: Secure GPT Inference with Function Secret Sharing ...
GPT Protocol: Verifiable Confidential AI Inference via AMD SEV-SNP ...
correct prompting is key, whatever GPT inference used | Sascha Radatz
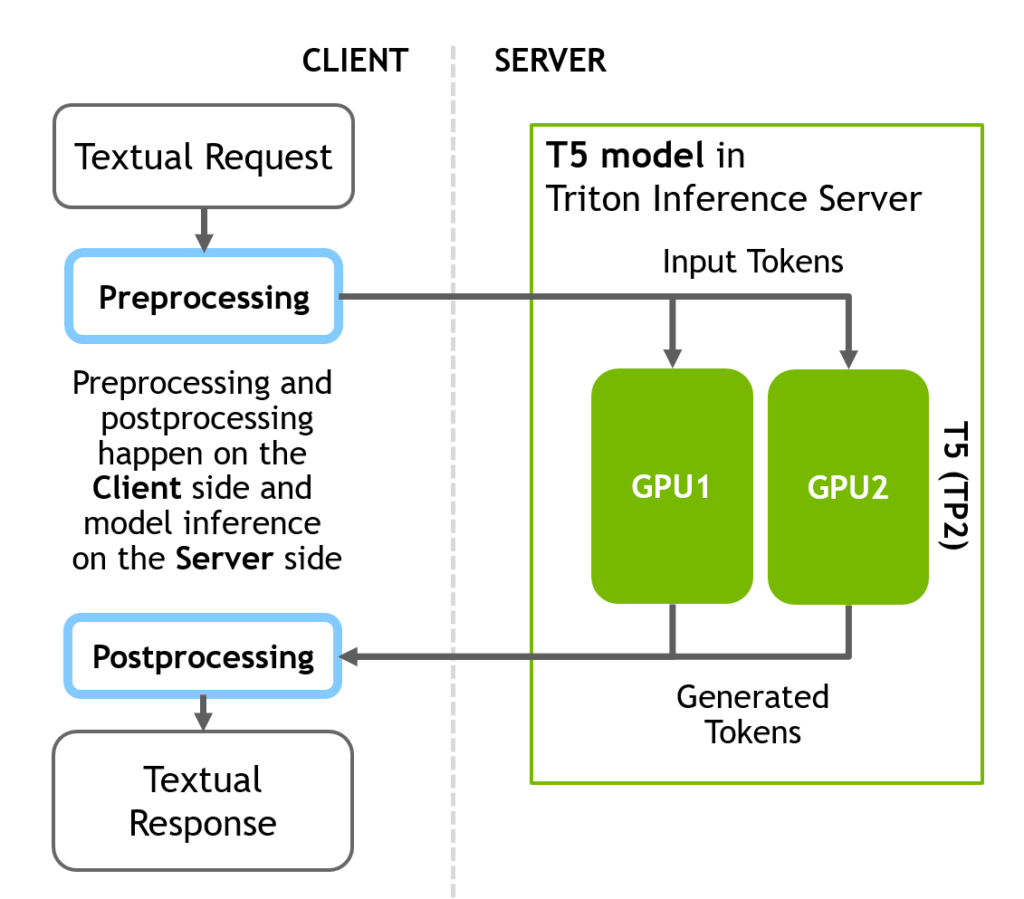
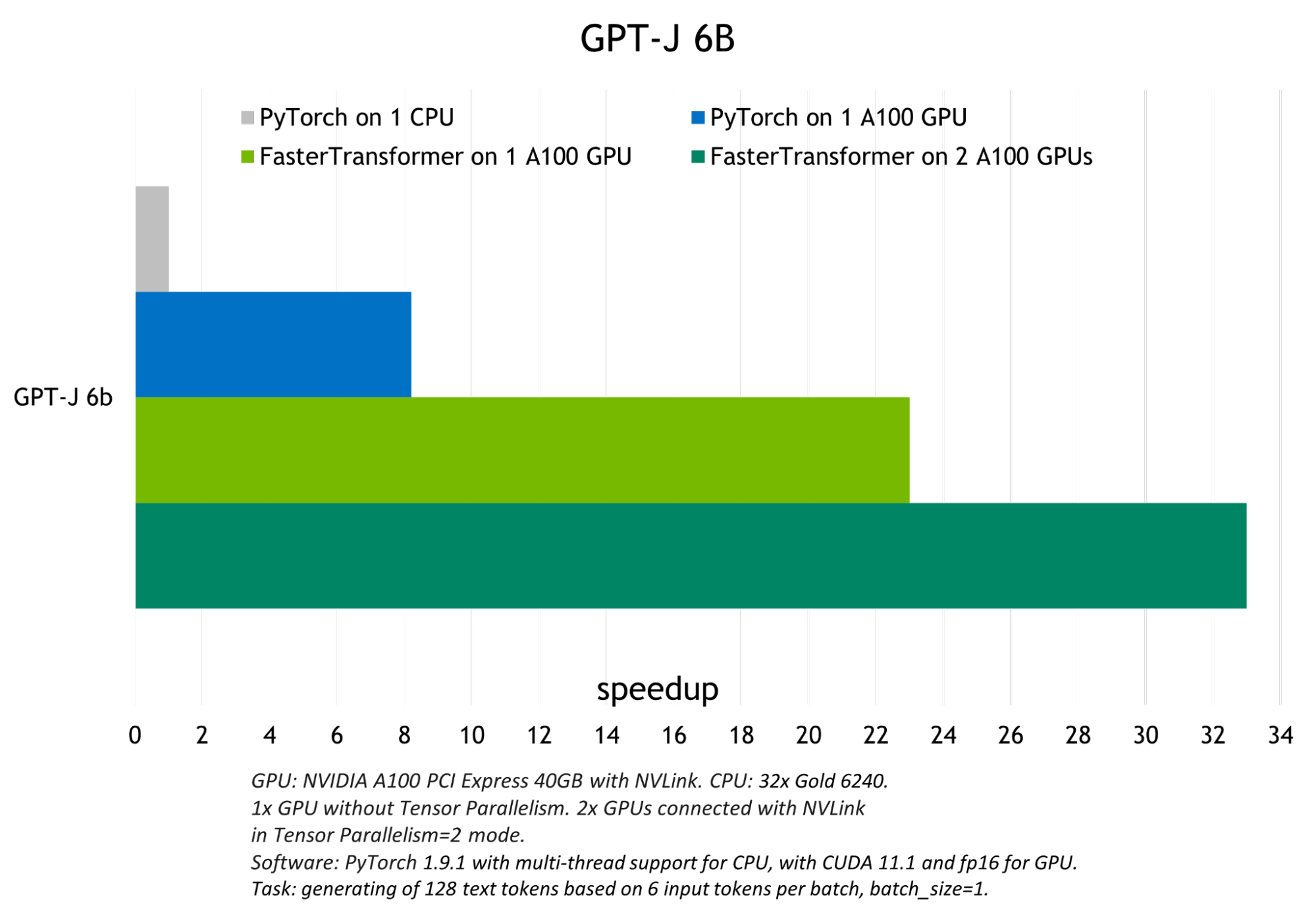
Deploying GPT-J and T5 with NVIDIA Triton Inference Server | NVIDIA ...
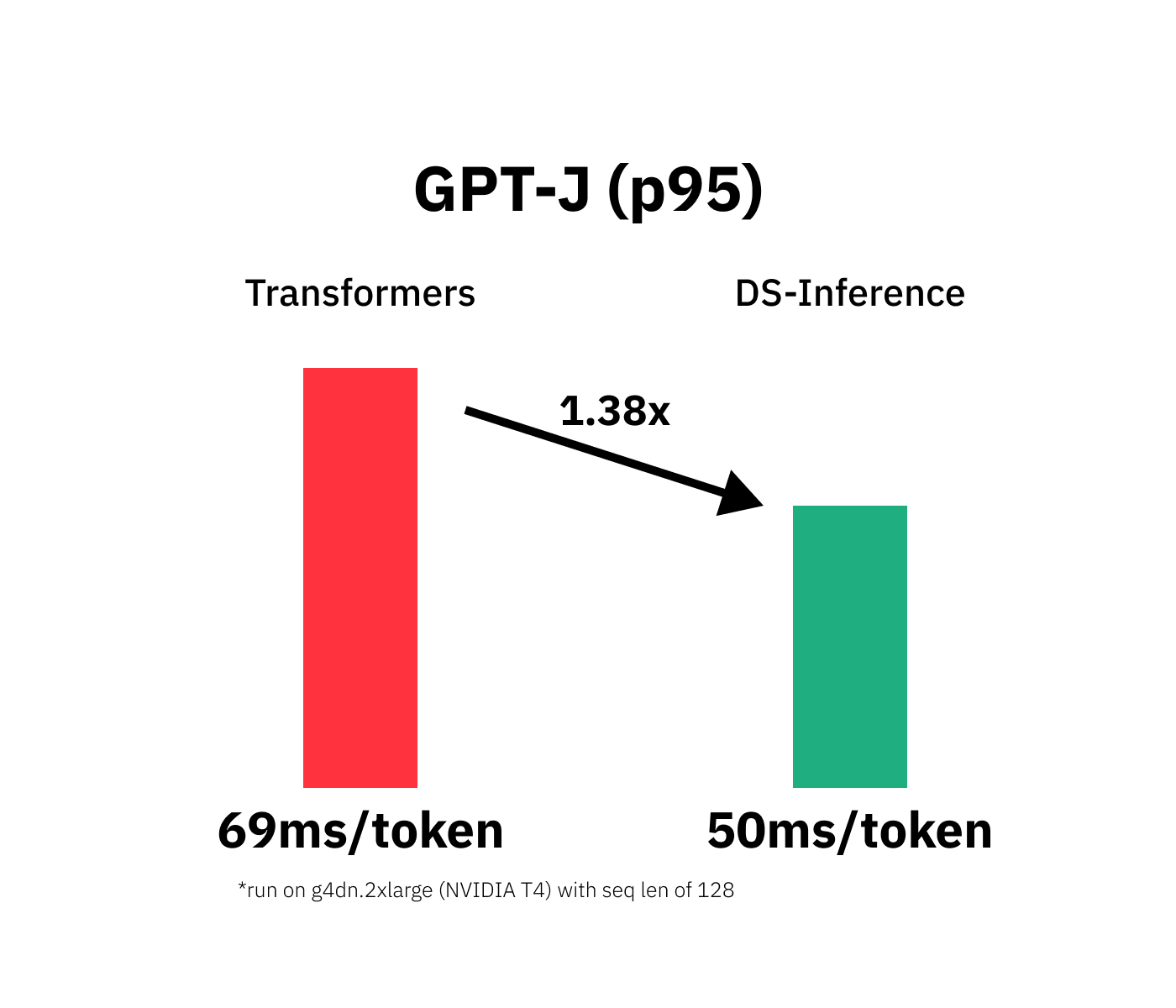
Accelerate GPT-J inference with DeepSpeed-Inference on GPUs
OpenAI GPT Models - Lei Mao's Log Book
Leading MLPerf Inference v3.1 Results with NVIDIA GH200 Grace Hopper ...
Understanding GPT: The Inference Perspective - YouTube
How Mantium achieves low-latency GPT-J inference with DeepSpeed on ...
GPT-OSS Inference from Scratch
Inference Compute: GPT-o1 and AI Governance
Accelerated Inference for Large Transformer Models Using NVIDIA Triton ...
Serverless vs. self-hosted LLM inference | LLM Inference Handbook
How to build a GPT model step-by-step guide .pdf
GitHub - dgsyrc/GPT-SoVITS-Inference-pack: A Lite release pack of GPT ...
GitHub - 0hq/WebGPT: Run GPT model on the browser with WebGPU. An ...
GPT-NeoX - DeepSpeed Inference
Speed up training and inference of GPT-Neo 1.6B by 45+% using DeepSpeed ...
Unexpected behavior of batched inference of GPT-J · Issue #53 · triton ...
Comparison of Inference Speed between Baseline GPT-Neo and Modified ...
GPT-J inference on the CPU using C/C++ : r/programming
GitHub - bstollnitz/gpt-transformer: A simple implementation of a GPT ...
Build Your Own GPT Model In 5 Easy Steps.pdf
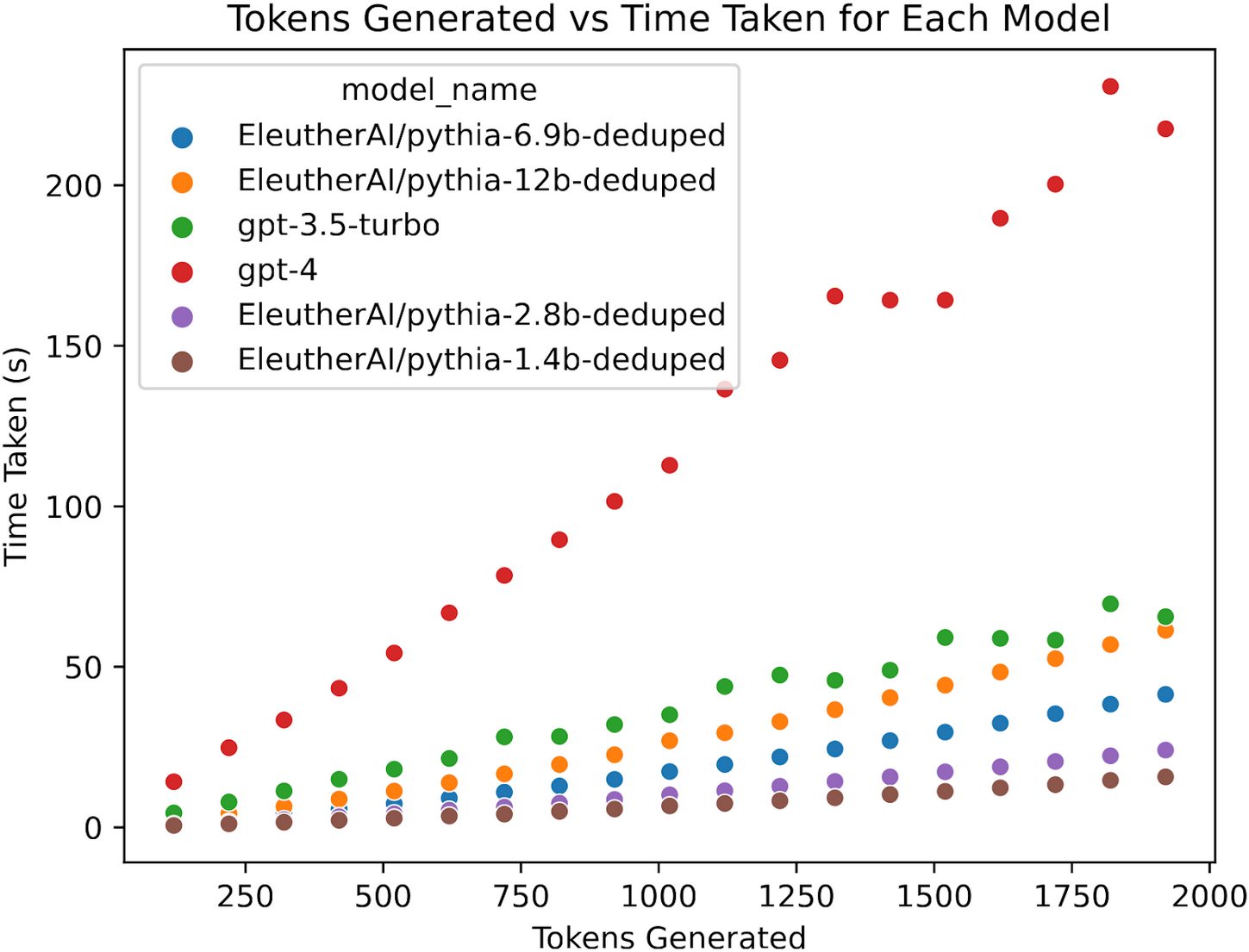
Nvidia, Groq, and Why "Inference" in GPT Models Now Matter More Than Ever
113上_專題成果影片_Efficient GPT-2 Inference on Alveo U280 Via High Level ...
NVIDIA Accelerates OpenAI gpt-oss Models Delivering 1.5 M TPS Inference ...
Figure 5 from A Scalable GPT-2 Inference Hardware Architecture on FPGA ...
gpt-oss – OpenAI’s Open-Source Inference Model Series | Alternative AI ...
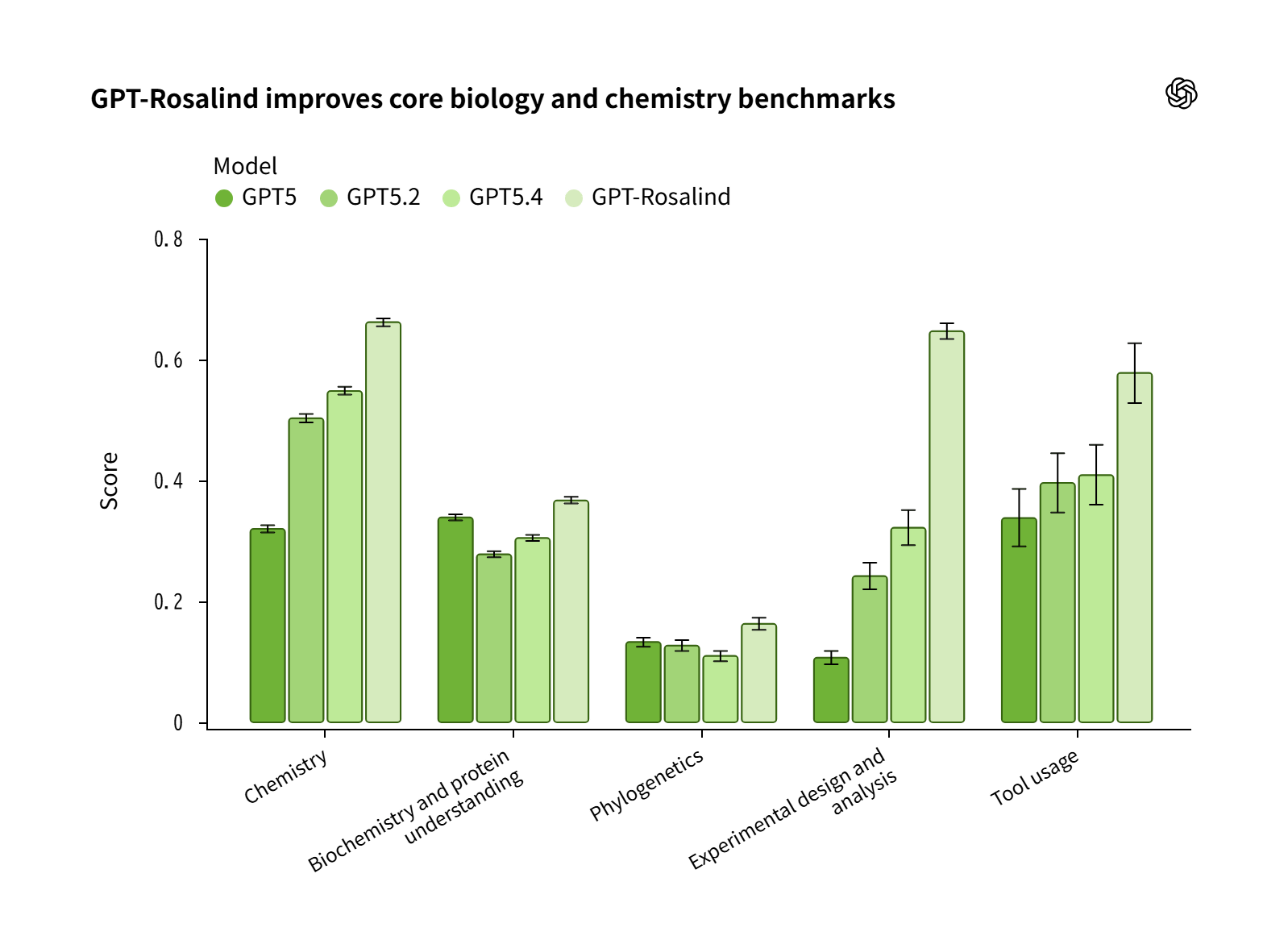
OpenAI announces 'GPT-Rosalind,' an inference AI model for life science ...
GPT-4 Architecture and Inference Costs | PDF | Artificial Intelligence ...
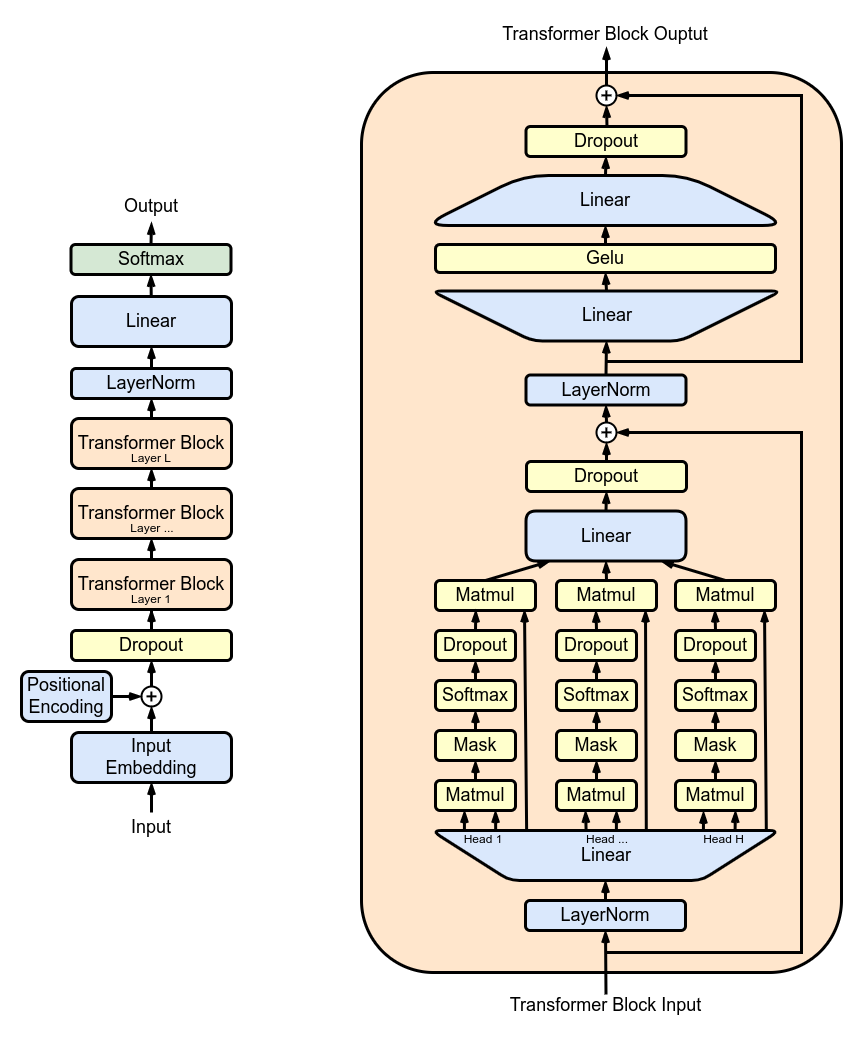
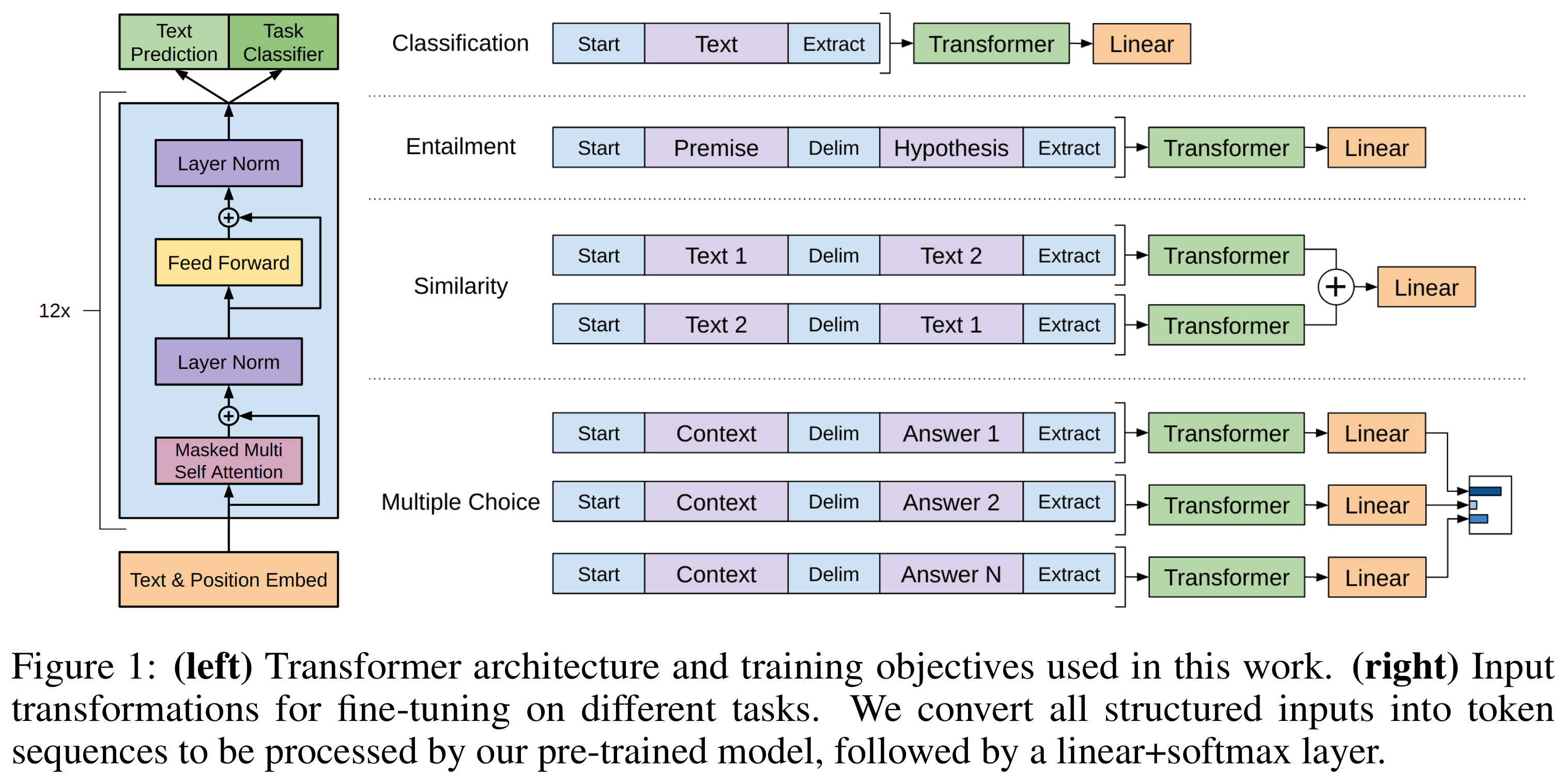
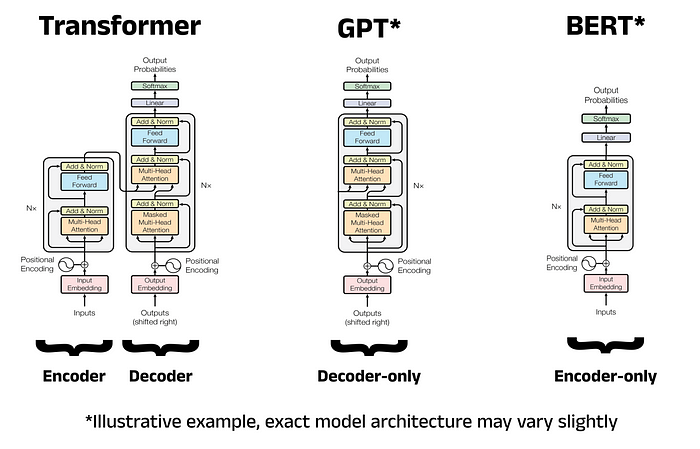
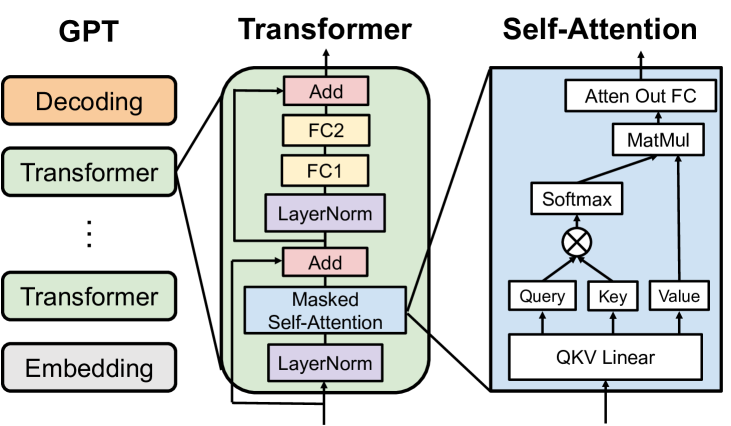
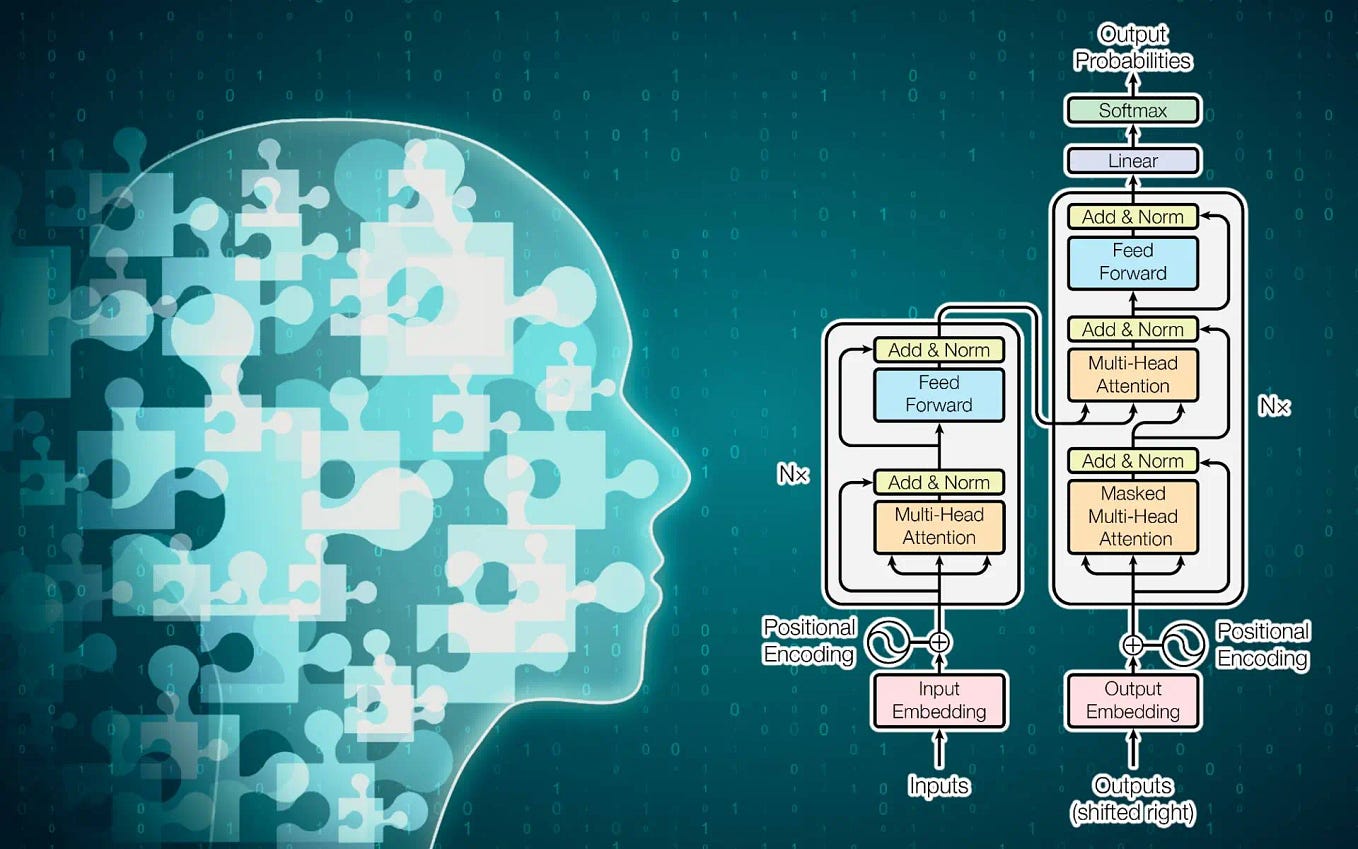
The Transformer Architecture of GPT Models | Towards Data Science
[BUG] GPT-Neo inference examples broken in Master · Issue #2248 ...
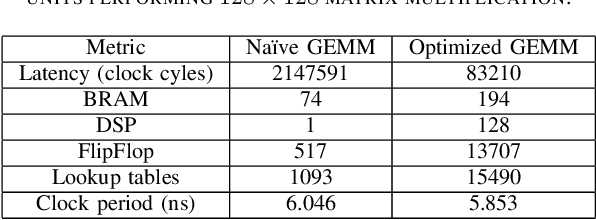
Table III from A Scalable GPT-2 Inference Hardware Architecture on FPGA ...
Conceptual architecture of a GPT model. | Download Scientific Diagram
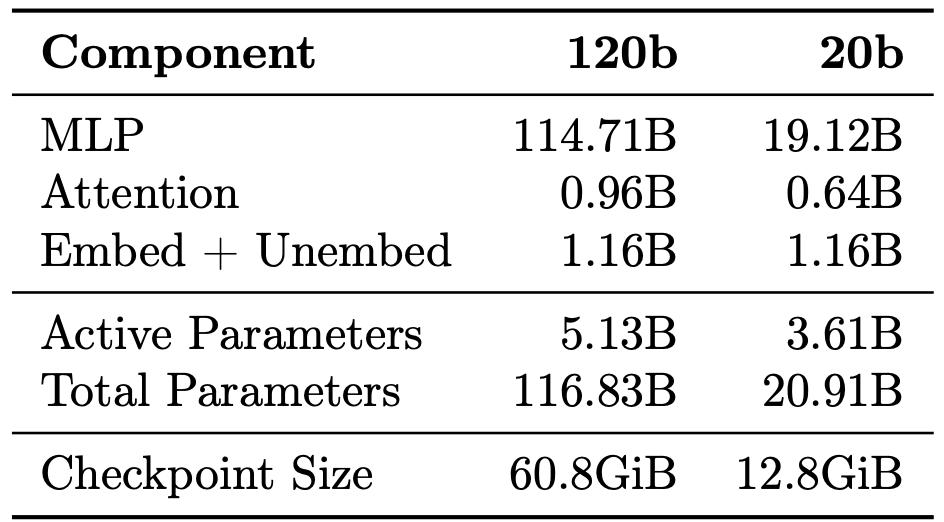
GPT-OSS 120B | Lambda Inference
Confirmed that GPT-5 is running inference on Nvidia GB200. According to ...
How to Train a GPT Model: A Comprehensive Guide | by LeewayHertz ...
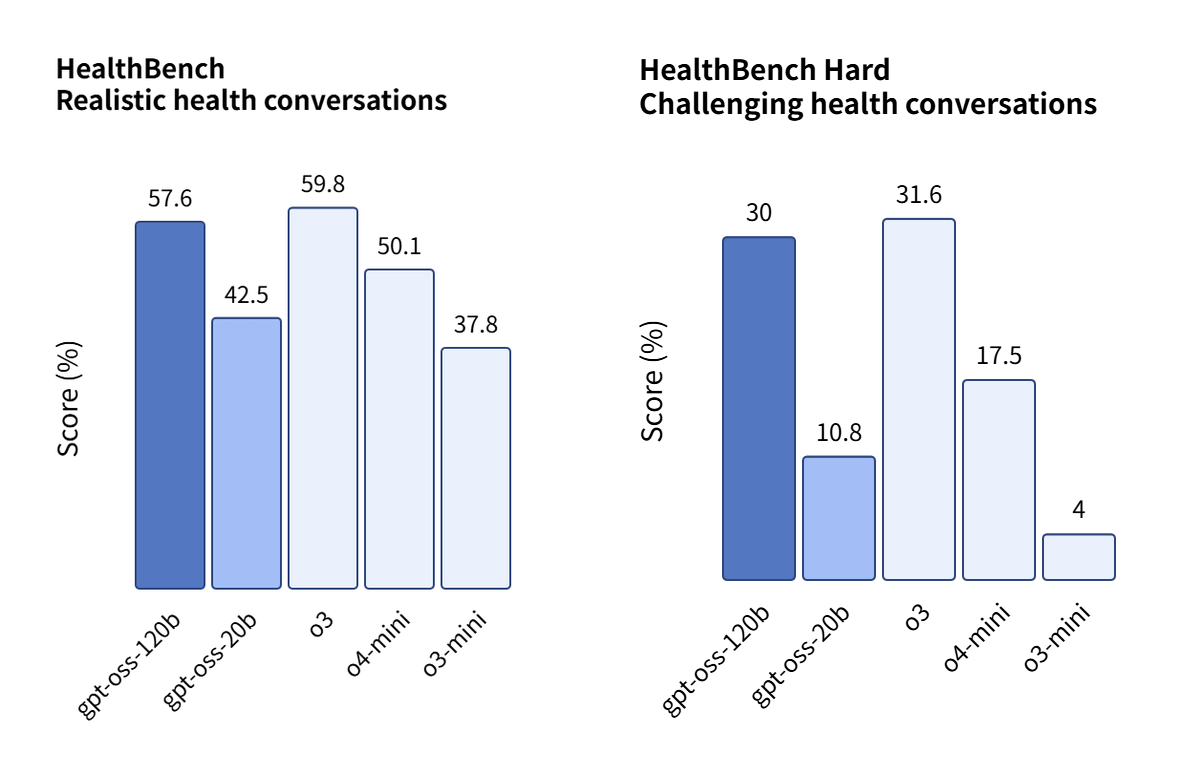
OpenAI announces OpenWeight AI inference model 'gpt-oss', lightweight ...
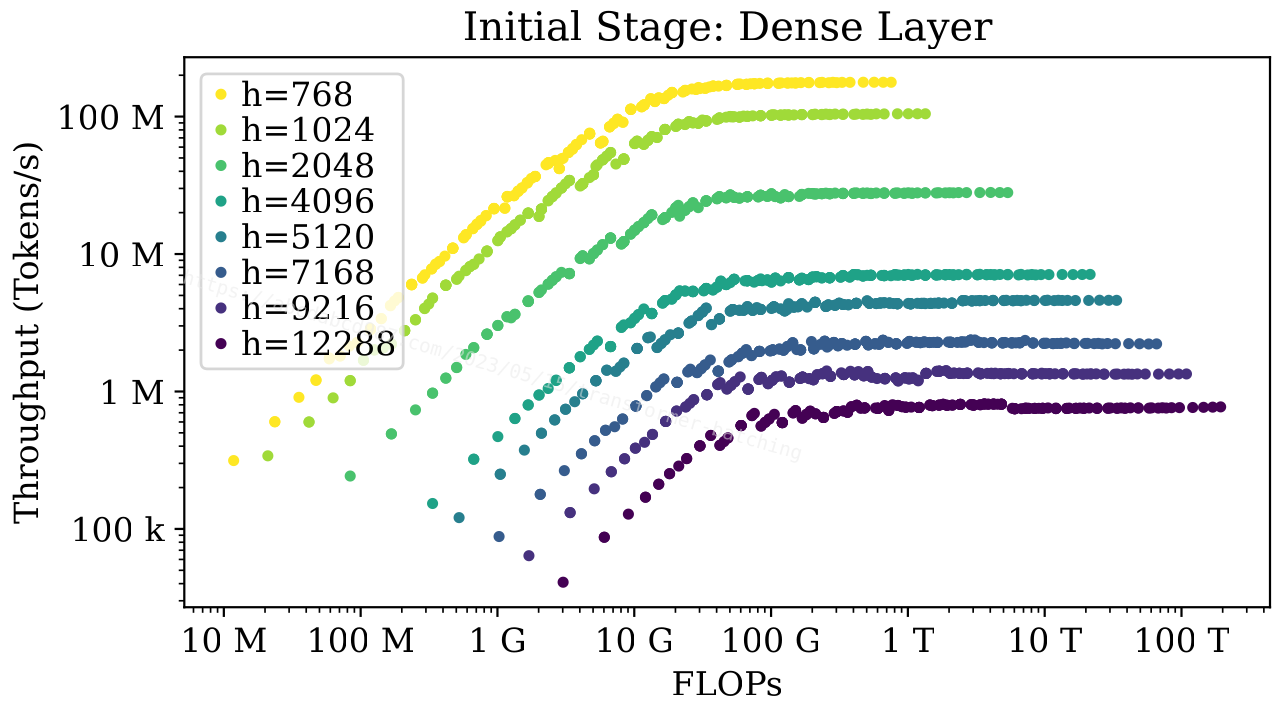
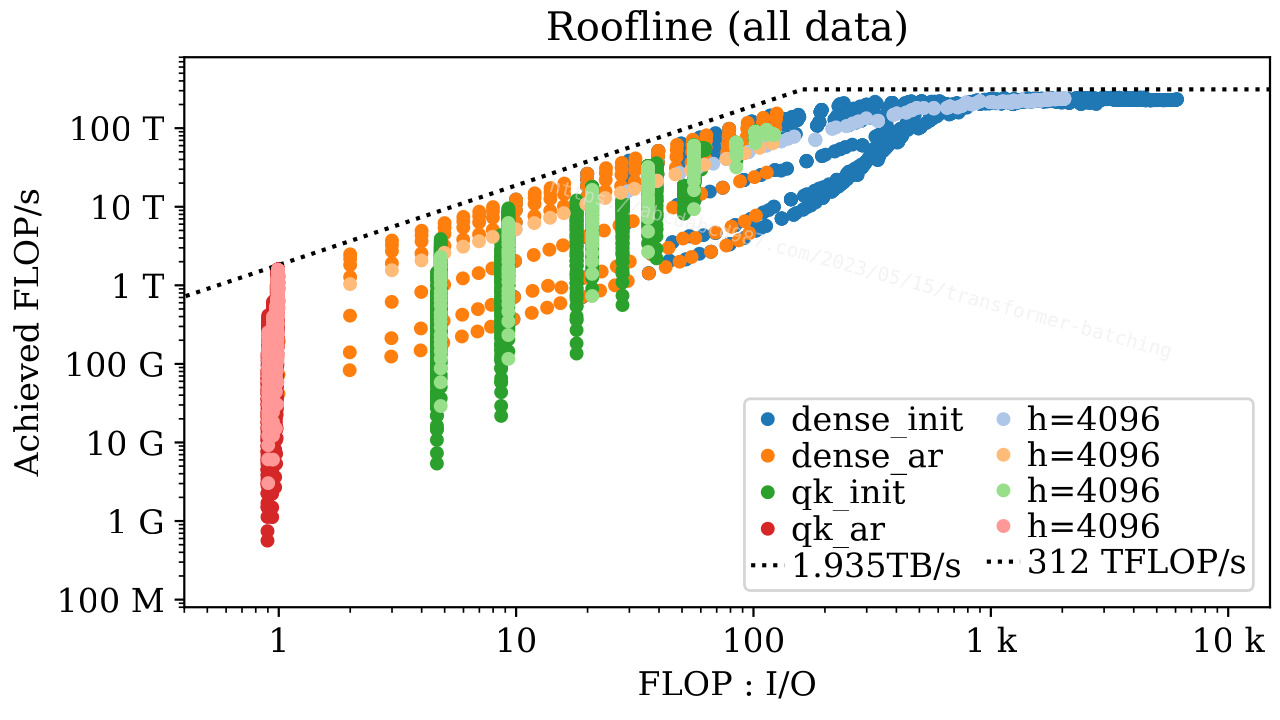
[2305.05920] Fast Distributed Inference Serving for Large Language Models
A showcase of utilizing GPT-4 and existing inference data to generate ...
about inference · Issue #30 · NExT-GPT/NExT-GPT · GitHub
GitHub - xorbitsai/inference: Replace OpenAI GPT with another LLM in ...
GPT - Intuitively and Exhaustively Explained | Towards Data Science
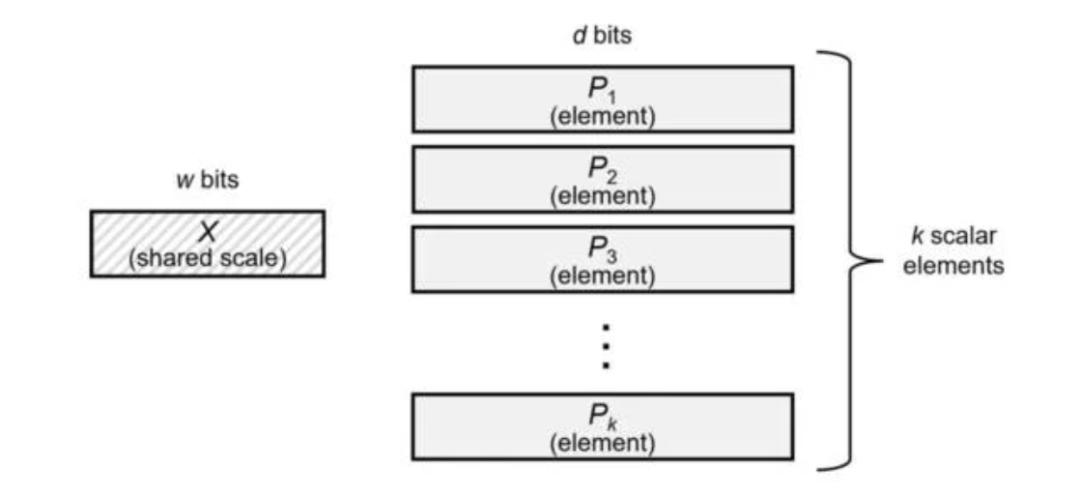
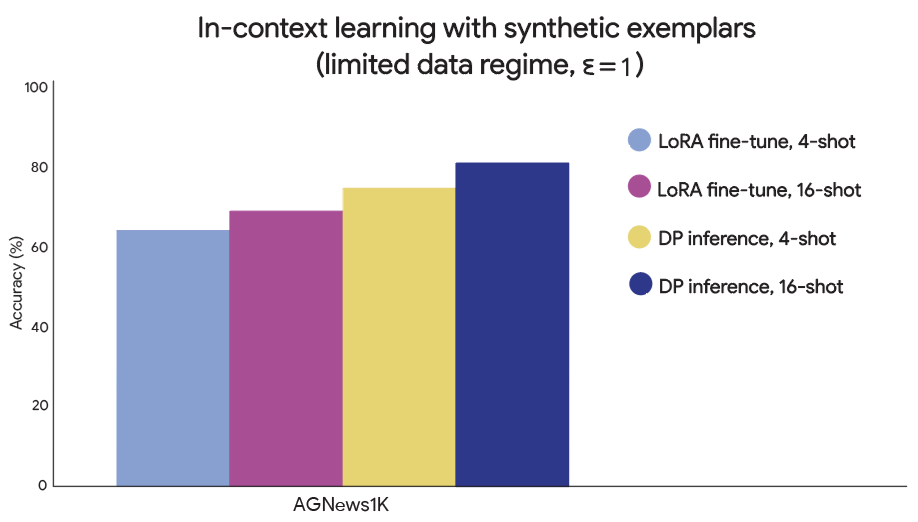
Generating synthetic data with differentially private LLM inference
(PDF) The Inference Capability of GPT-4 in DIKWP
Figure 4 from A Scalable GPT-2 Inference Hardware Architecture on FPGA ...
Models | Machine Learning Inference | Deep Infra
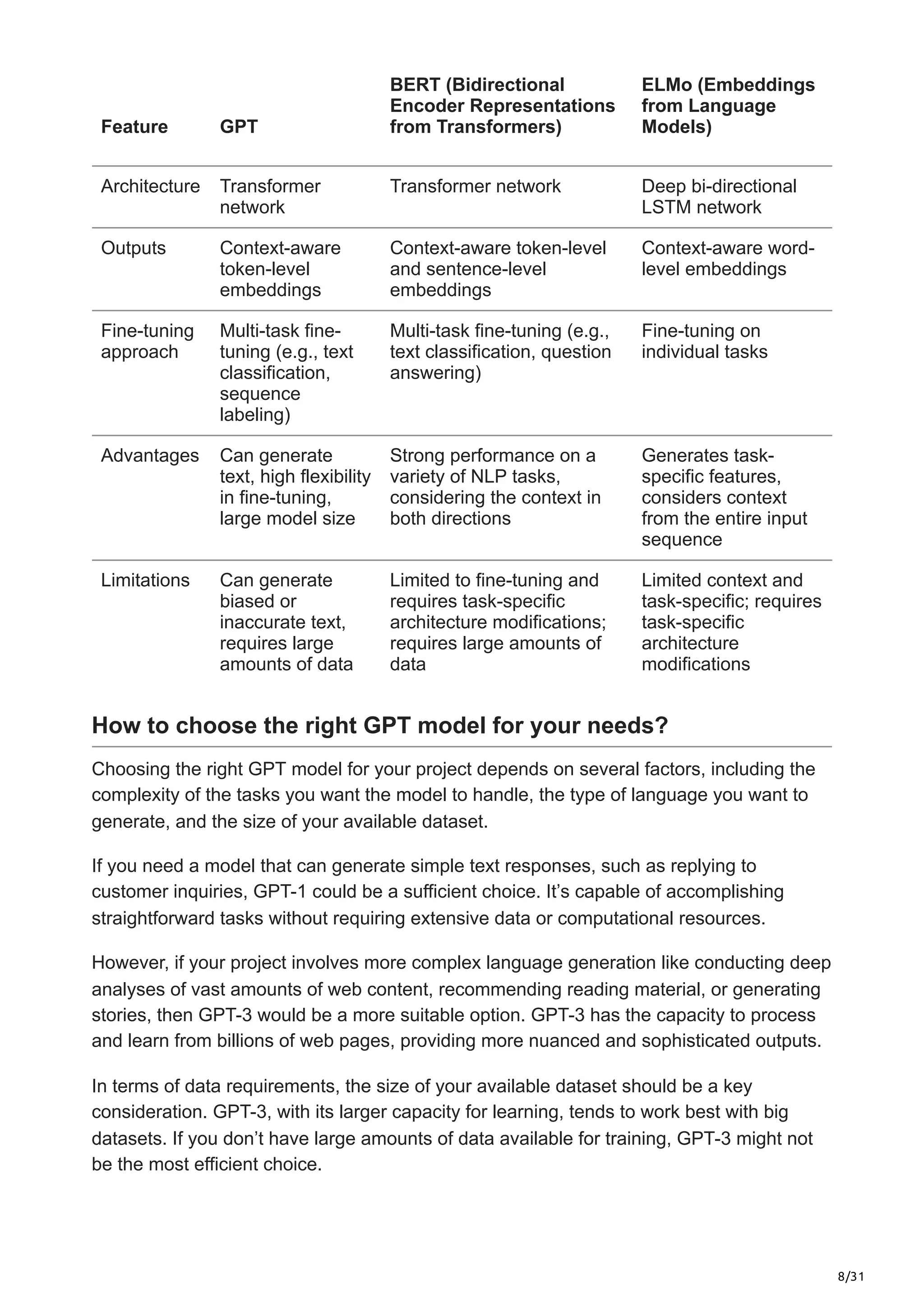
[How Algorithms Drive GPT Models] A Look at Training, Fine-Tuning ...
The flowchart illustrates two processesThe flowchart of the GPT ...
How to build a custom GPT in 2025: A step-by-step guide with examples ...
Table II from A Scalable GPT-2 Inference Hardware Architecture on FPGA ...
NExT-GPT
Illustrating our high-level idea: Using GPT-3 for transductive ...
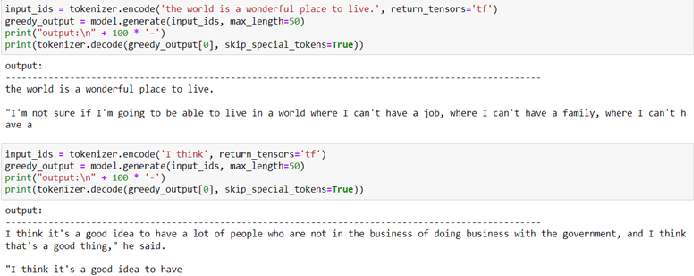
Fine-Tuning a Pre-Trained GPT-2 Model and Performing Inference: A Hands ...
gpt-j/inference.py at main · graphcore/gpt-j · GitHub
Blog | FLAML
GPT-SoVITS-Inference/api_doc.md at stable · X-T-E-R/GPT-SoVITS ...
GitHub - X-D-Lab/GPT_SoVITS_Inference
GitHub - lioarce01/gpt-inference-engine: OpenAI-compatible REST API for ...
What will GPT-2030 look like?
DeepSpeed-MII: instant speedup on 24,000+ open-source DL models with up ...
12张图表解读2025年人工智能的发展状况 | 新闻资讯 | 微纳视界 - 微纳制造综合服务平台
The two models fueling generative AI products: Transformers and ...
inference_gui.py · yuoop/GPT-SoVITS-v2 at main
GitHub - Rostar-github/gpt2-inference
KG-GPT: Reasoning with Knowledge Graphs | PDF | Image Segmentation ...
GPT-GPT2 Roadmap – Vikas Kumbharkar – Manifesting machine learning ...
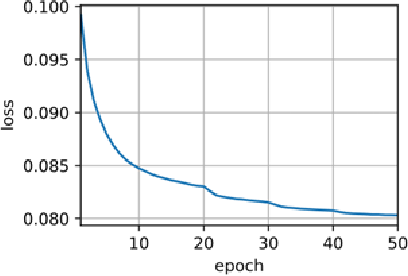
Integrating commonsense inferences into a GPT2-based generative model ...
GPT家族的奇妙冒险:从会说话的小不点到智慧巨人的成长记 – 天天悦读
GPT2-WebGL: WebGL로 구현한 GPT-2 추론(inference) 실행 및 시각화 프로젝트 - 읽을거리&정보공유 ...
Step-by-step workflow diagram for applying GPT. Step1 is to register ...
MindSpore-GPT/inference.py at main · dolphin-Dang/MindSpore-GPT · GitHub
Getting Started with Edge AI on NVIDIA Jetson: LLMs, VLMs, and ...
From Theory to Code: Step-by-Step Implementation and Code Breakdown of ...
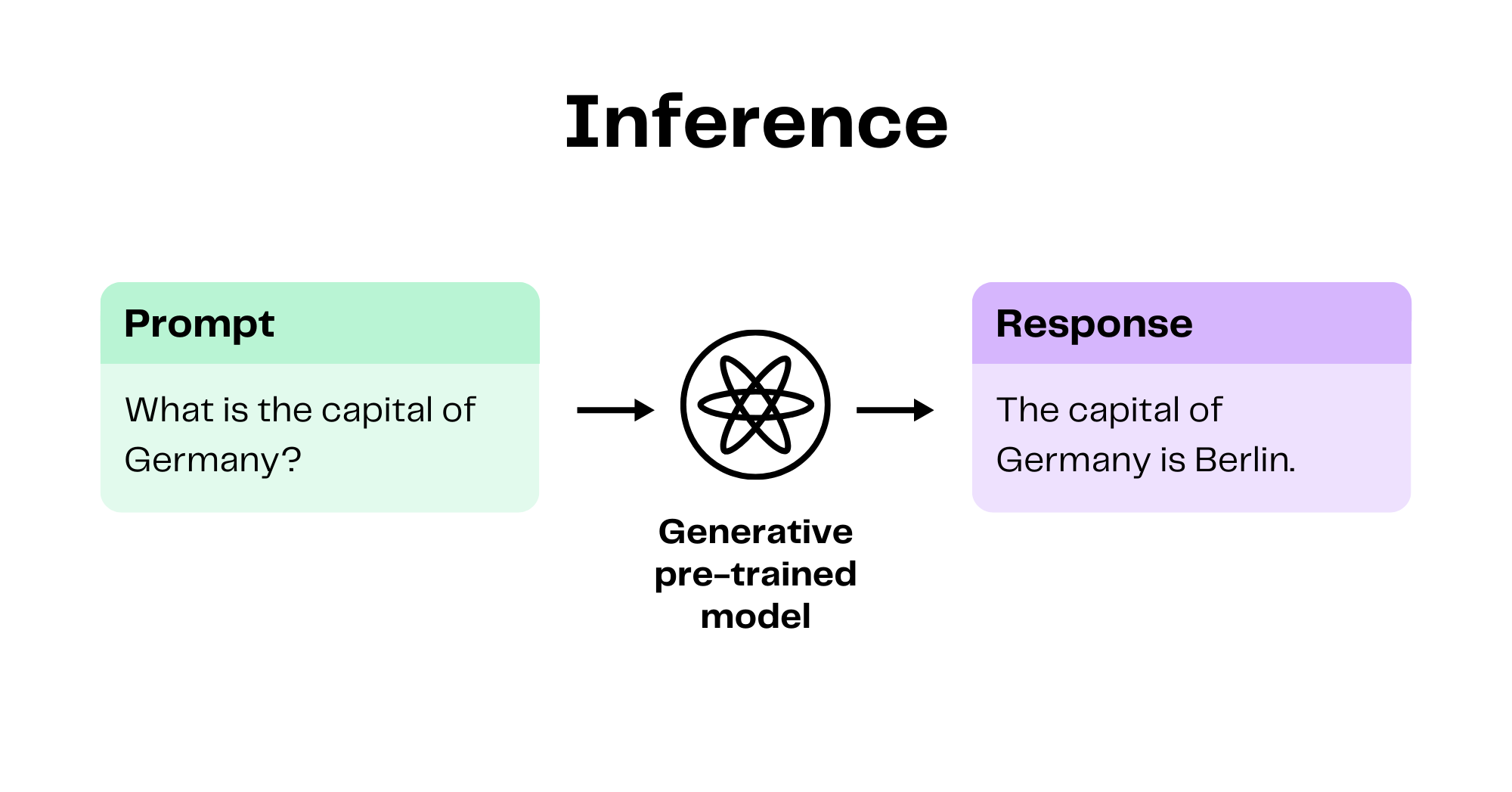
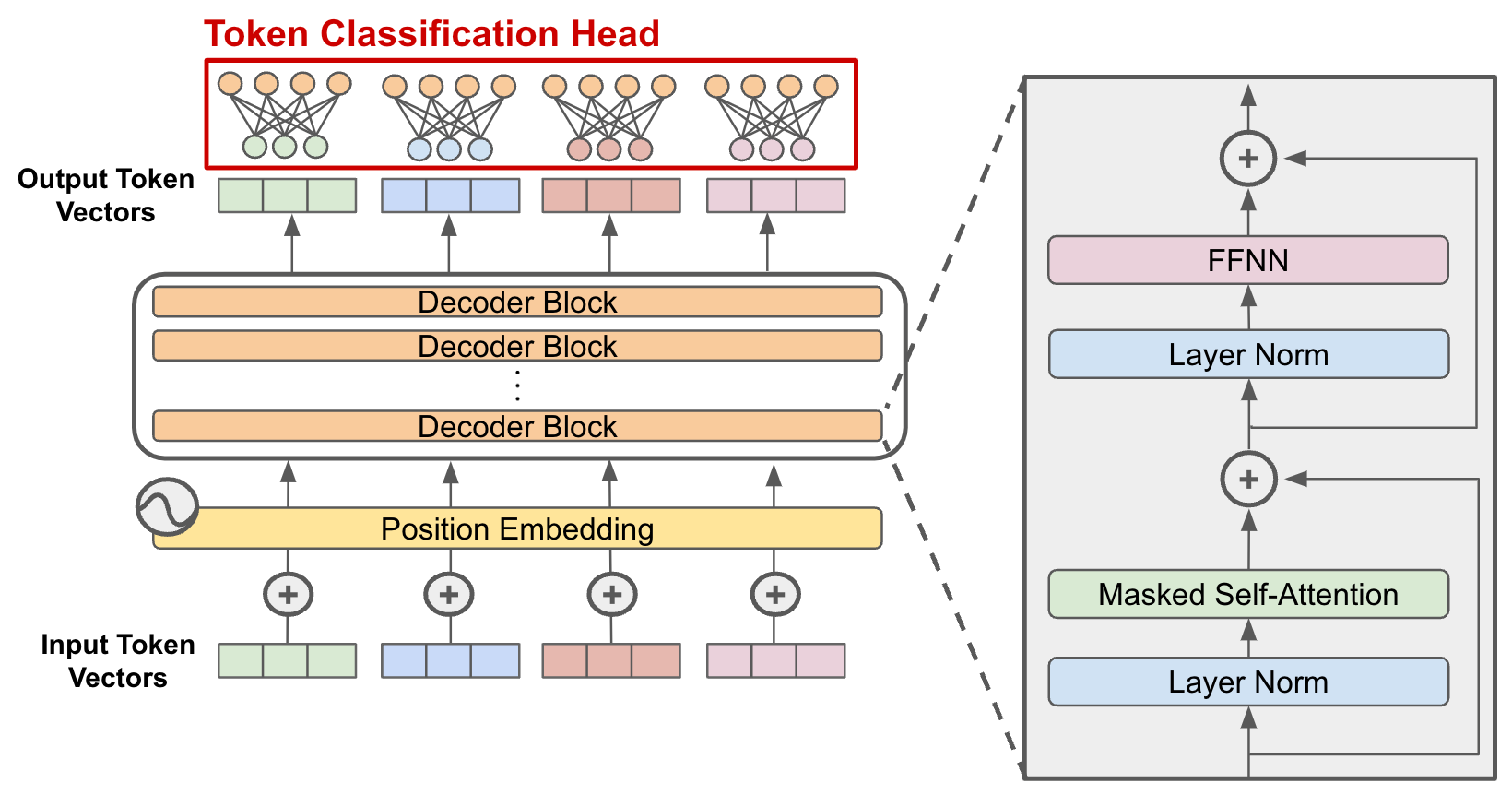
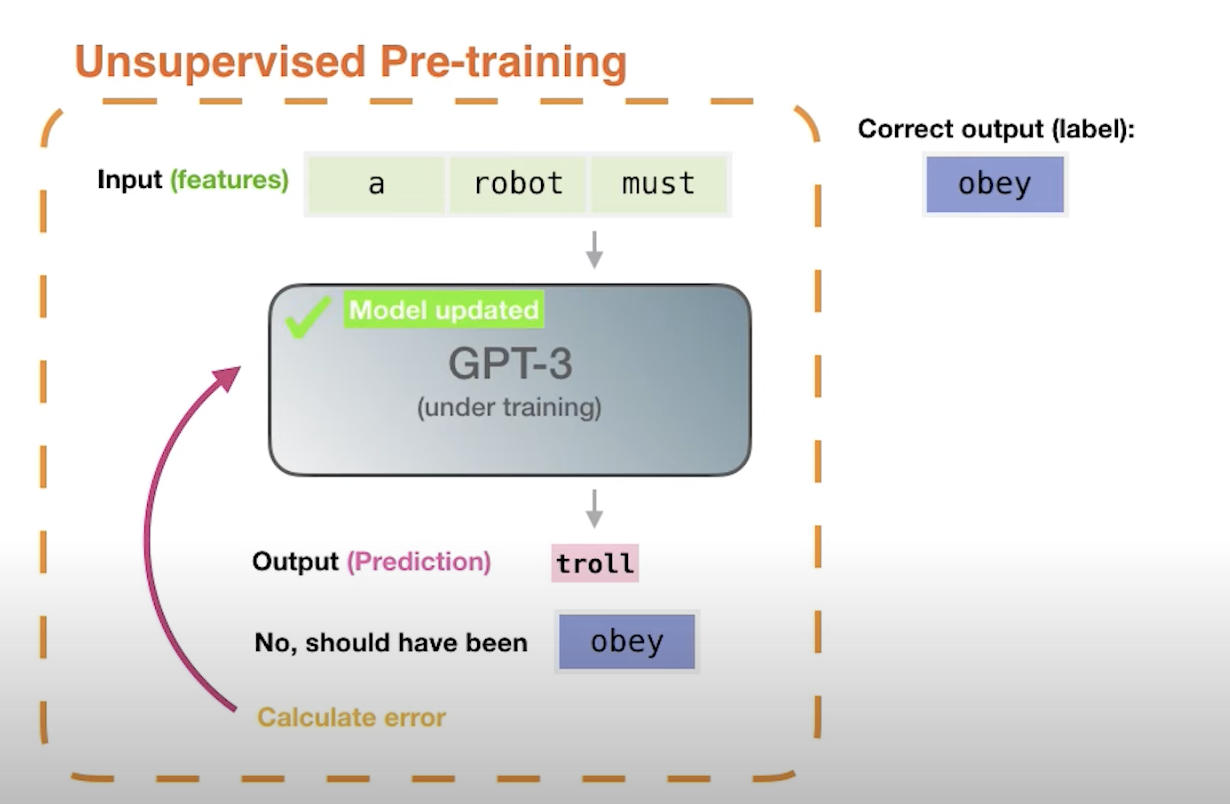
Aman's AI Journal • Primers • Generative Pre-trained Transformer (GPT)
GitHub - Apauto-to-all/GPT-soVITS-Inference-batchTool: 这是一个批量推理工具 ...
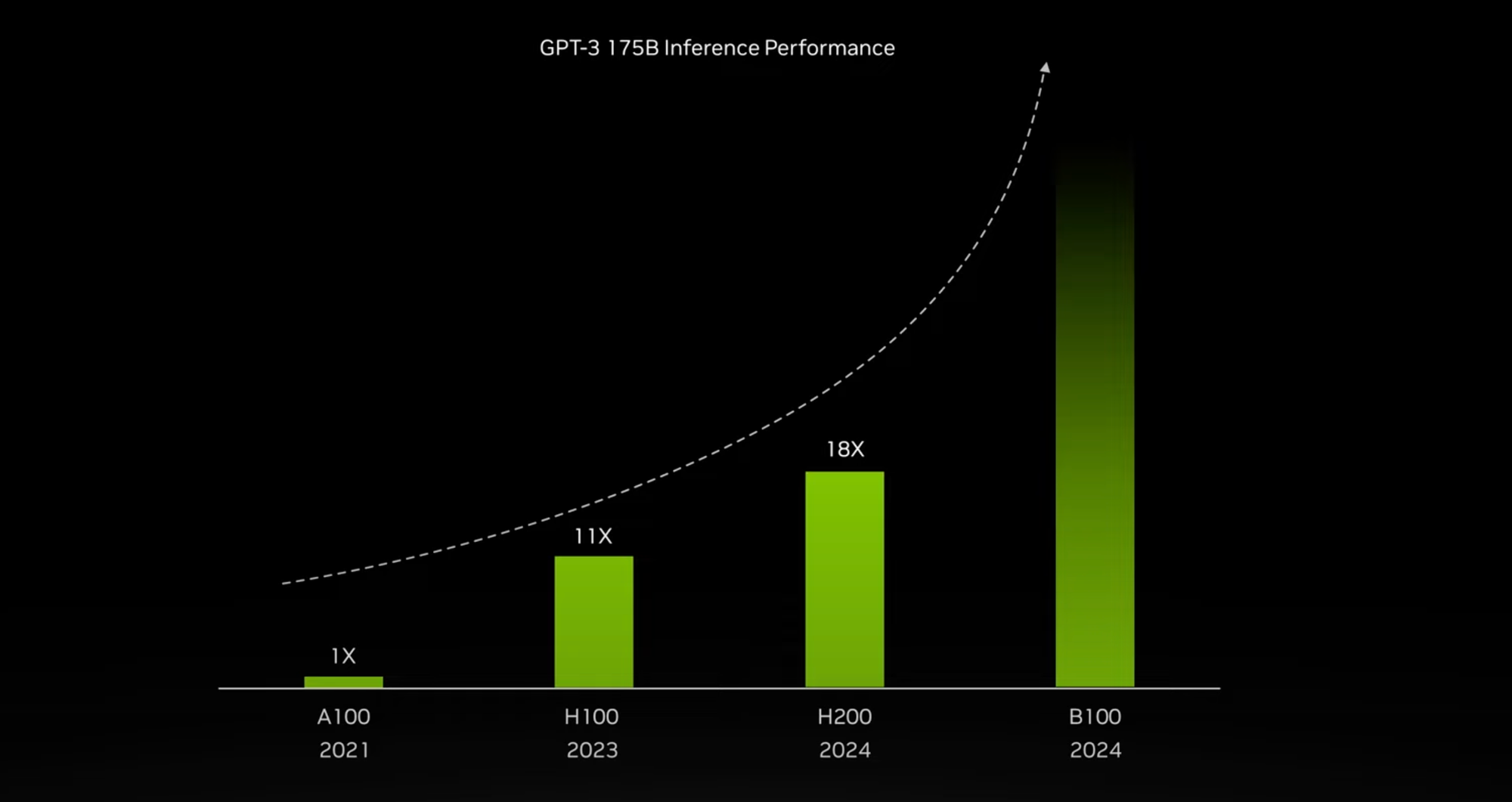
NVIDIA Unveils Next-Generation HGX H200 AI Chip
















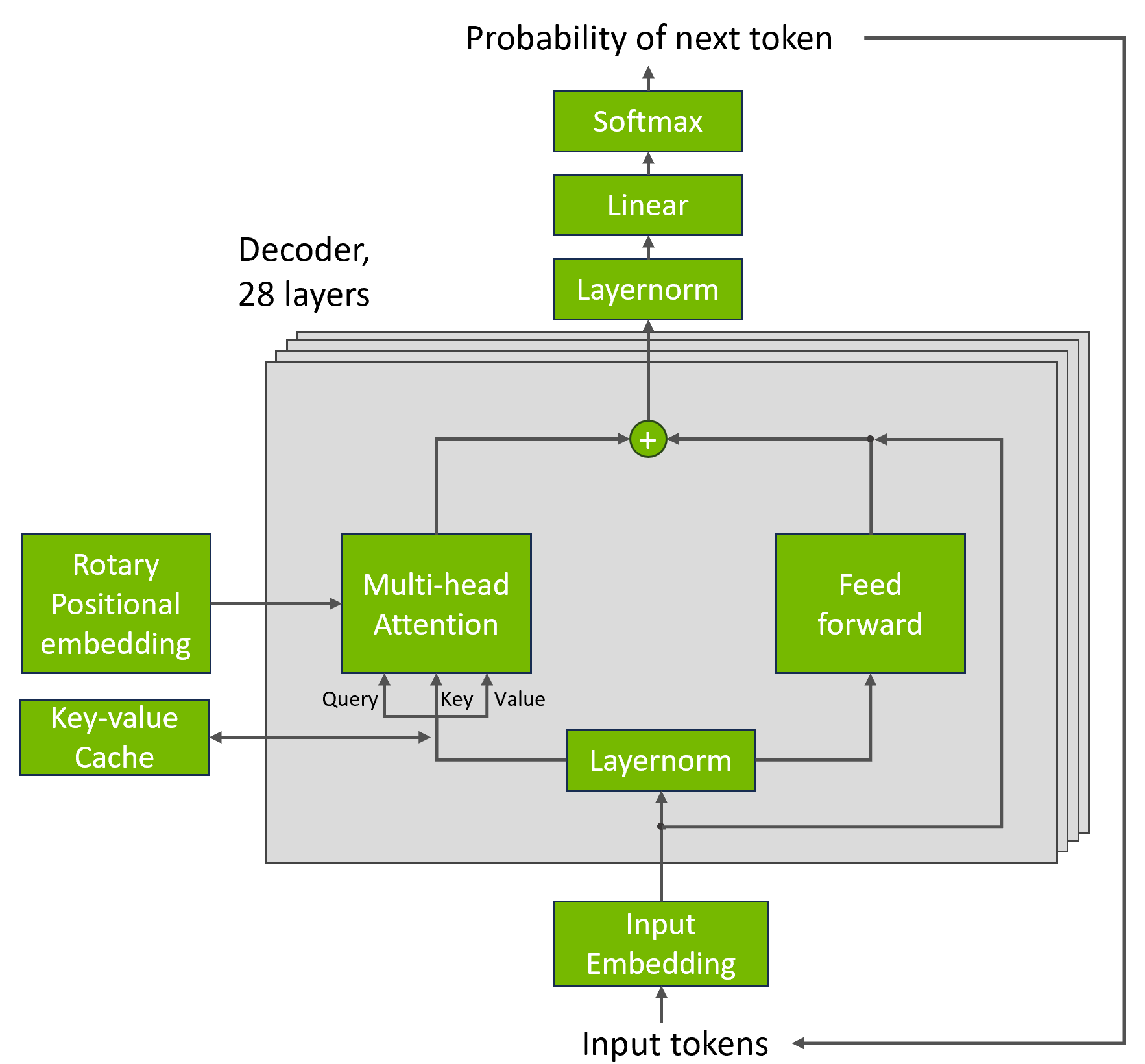

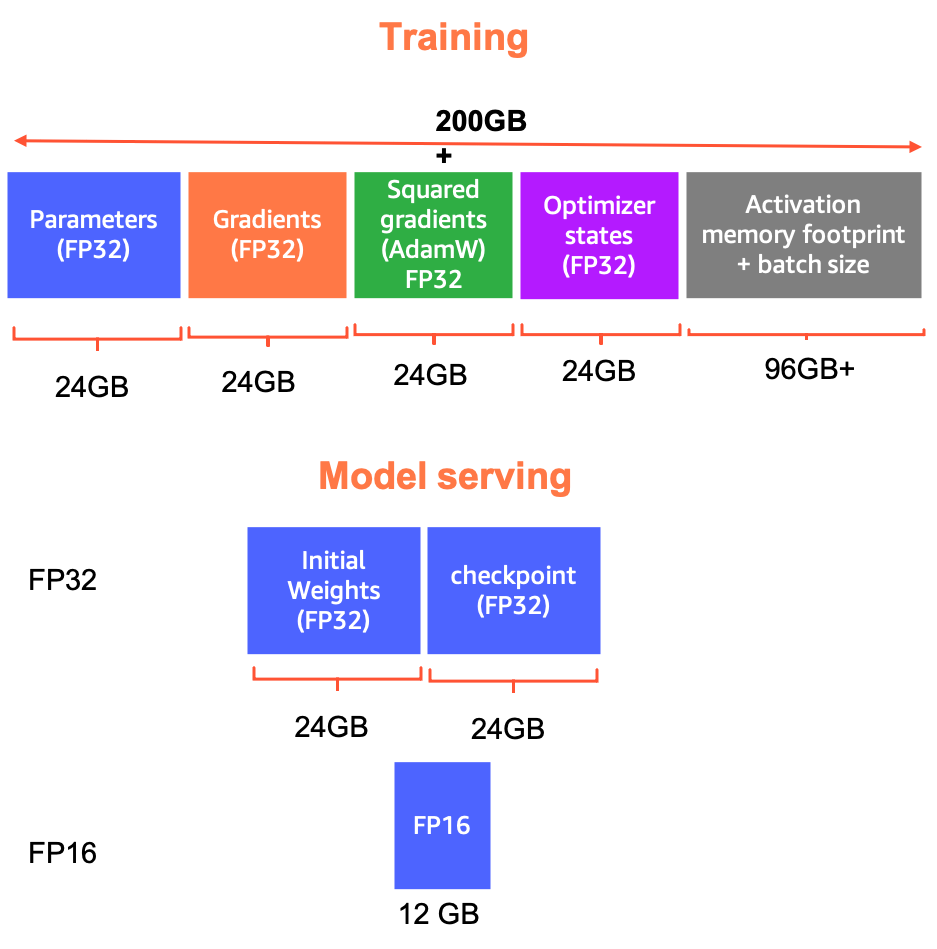
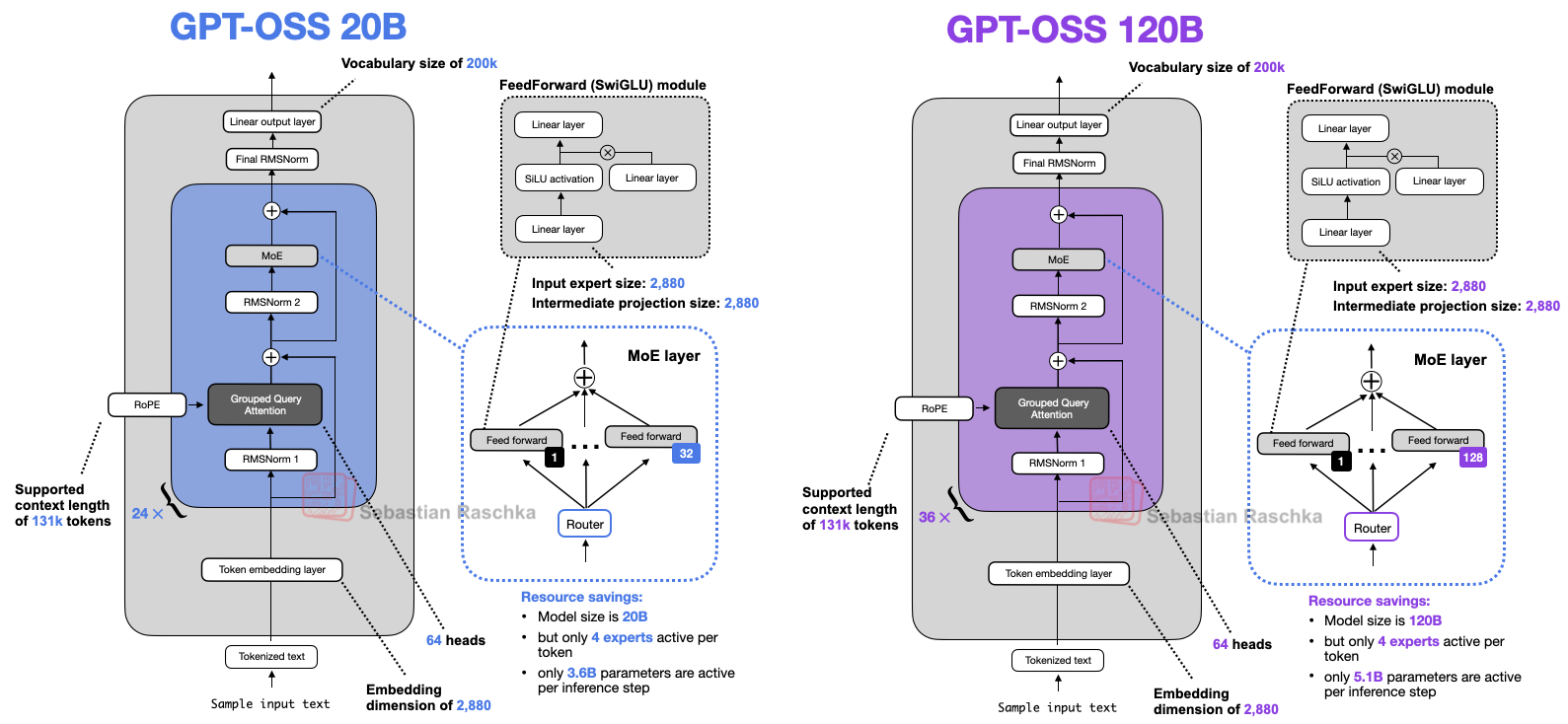

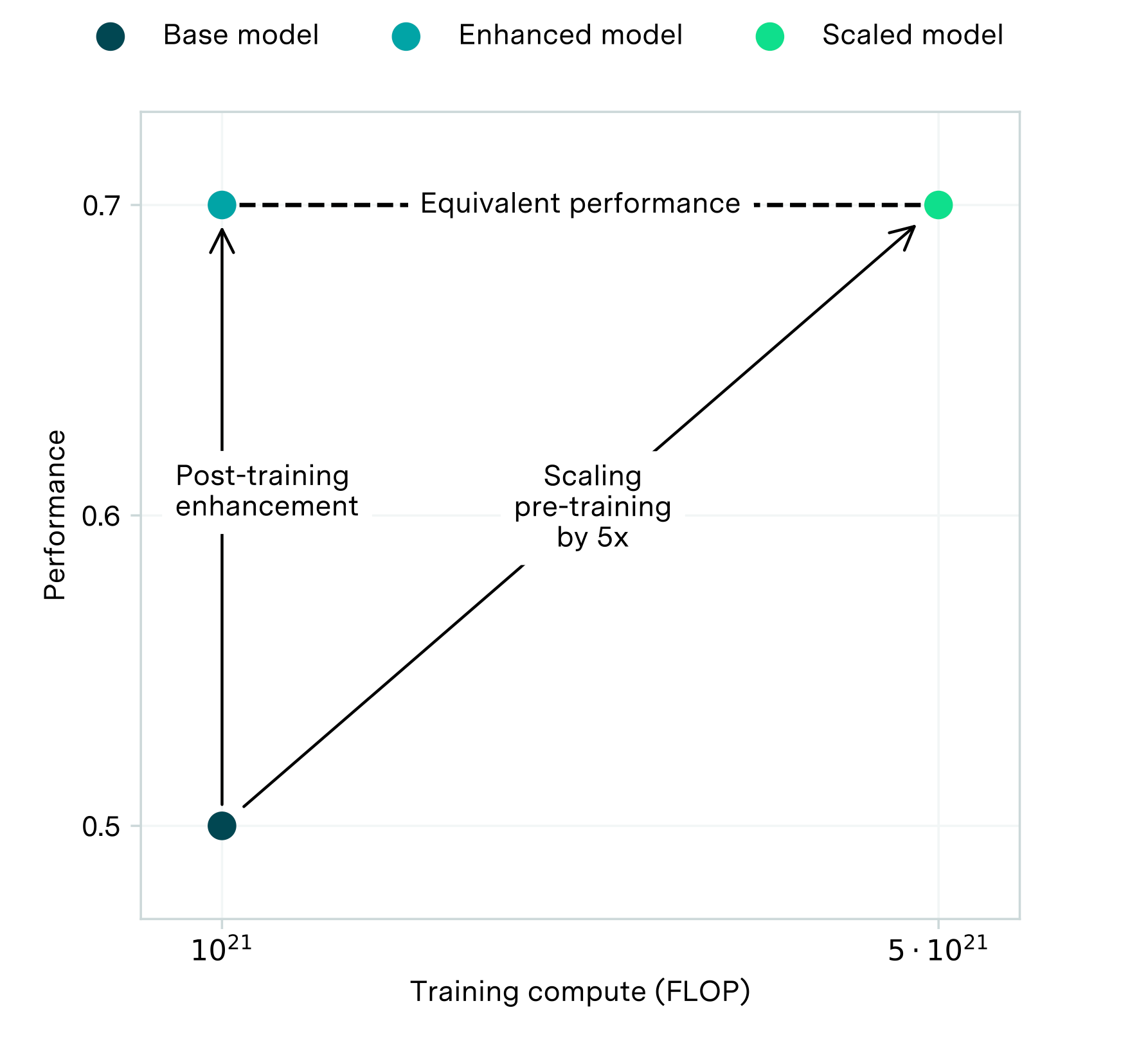


































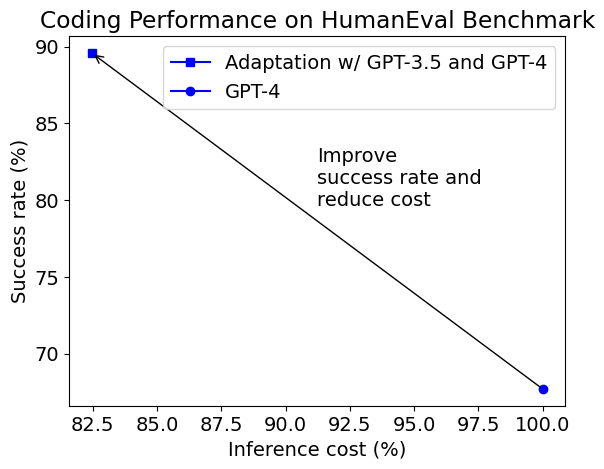
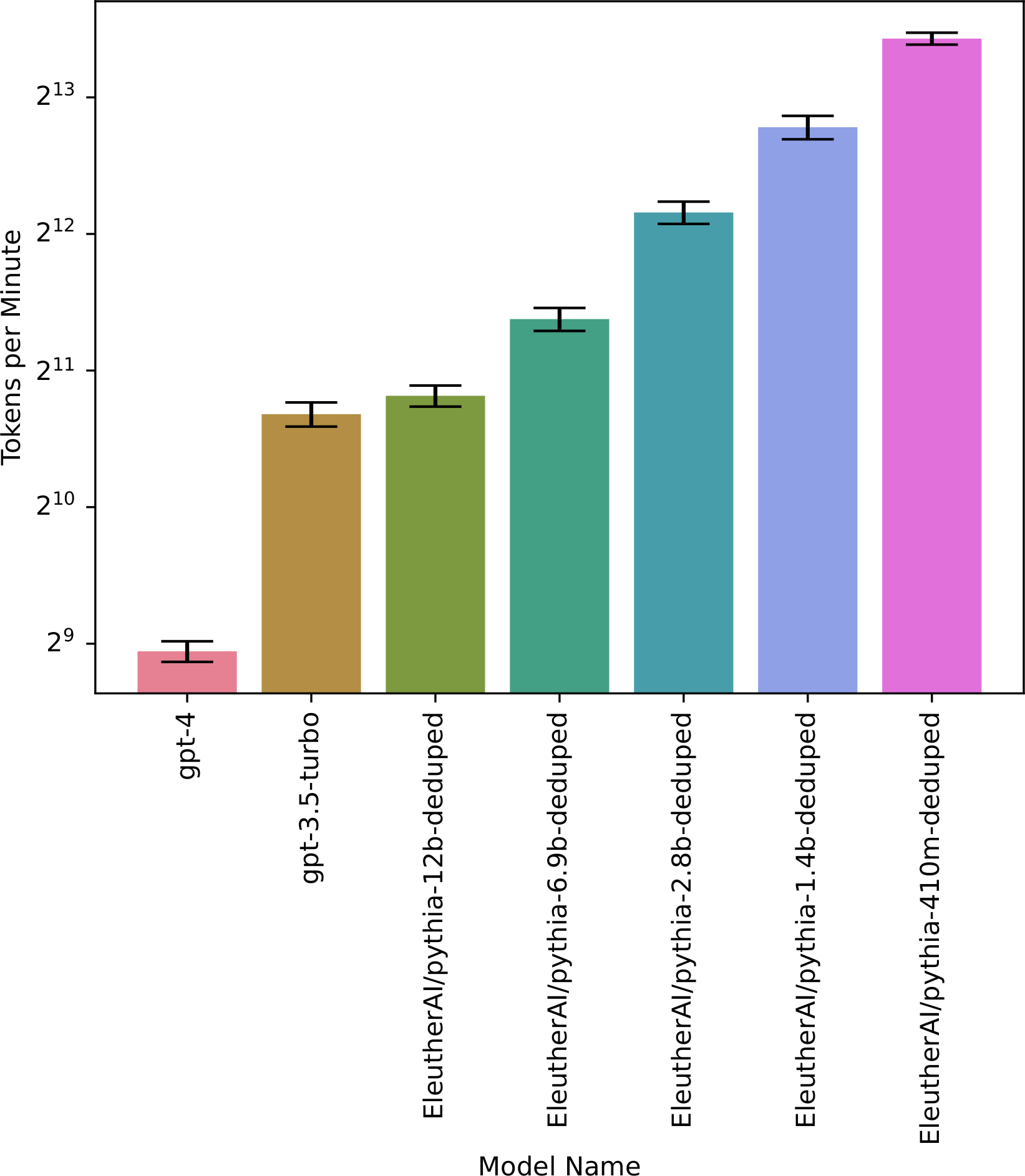
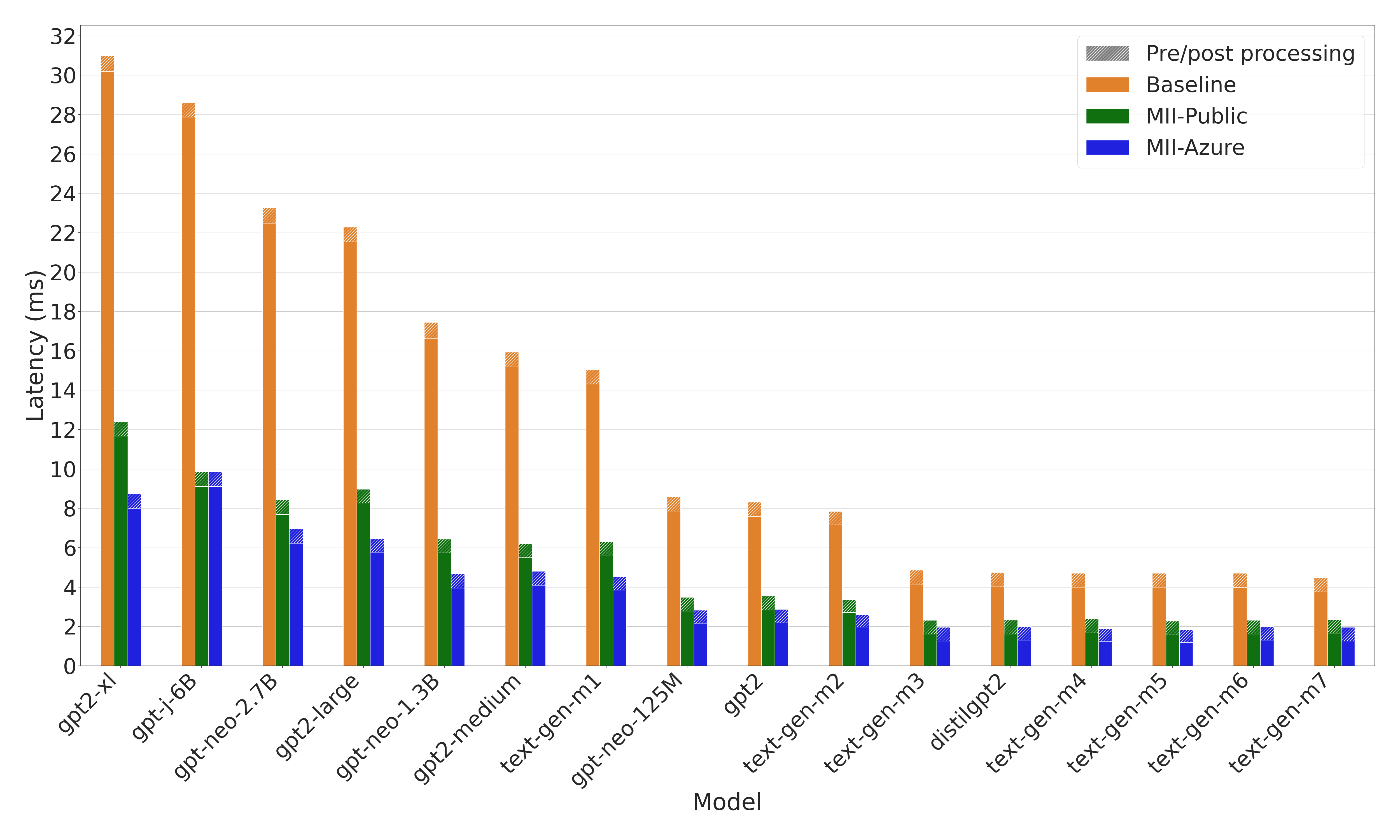









{kind=link}